
Paper note [Week 2]
Simple-BEV: What Really Matters for Multi-Sensor BEV Perception?
[ICRA 2023]
Motivation
- Focus on innovating new techniques for “lifting” features from the 2D image plane(s) onto the BEV plane
- What about RGB and Radar?
Contribution
Elucidate high-impact factors in the design and training protocol of BEV perception models.
1
Propose a model where the “lifting” step is parameter-free and does not rely on depth estimation: we simply define a 3D volume of coordinates over the BEV plane, project these coordinates into all images, and average the features sampled from the projected locations. When this simple model is tuned well, it exceeds the performance of state-of-the-art models while also being faster and more parameter-efficient.
Demonstrate that radar data can provide a large boost to performance with a simple fusion method, and invite the community to re-consider this commonly-neglected part of the sensor platform.
Method
Lifting strategy: Our model is “simpler” than related work, particularly in the 2D-to-3D lifting step, which is handled by (parameter-free) bilinear sampling. This replaces, for example, depth estimation followed by splatting, MLPs, or attention mechanisms. Our strategy can be understood as “Lift-Splat without depth estimation”, but as as illustrated in Figure 1, our implementation is different in a key detail: our method relies on sampling instead of splatting. Our method begins with 3D coordinates of the voxels, and takes a bilinear sample for each one. As a result of the camera projection, close-up rows of voxels sample very sparsely from the image (i.e., more spread out), and far-away rows of voxels sample very densely (i.e., more packed together), but each voxel receives a feature. Splattingbased methods begin with a 2D grid of coordinates, and “shoot” each pixel along its ray, filling voxels intersected by that ray, at fixed depth intervals. As a result, splatting methods yield multiple samples for up-close voxels, and very few samples (sometimes zero) for far-away voxels. As we will show in experiments, this implementation detail has an impact on performance, such that splatting is slightly superior at short distances, and sampling is slightly superior at long distances. In the experiments, we also evaluate a recently-proposed deformable attention strategy, which is similar to bilinear sampling but with learned sampling kernel for each voxel (i.e., learned weights and learned offsets).
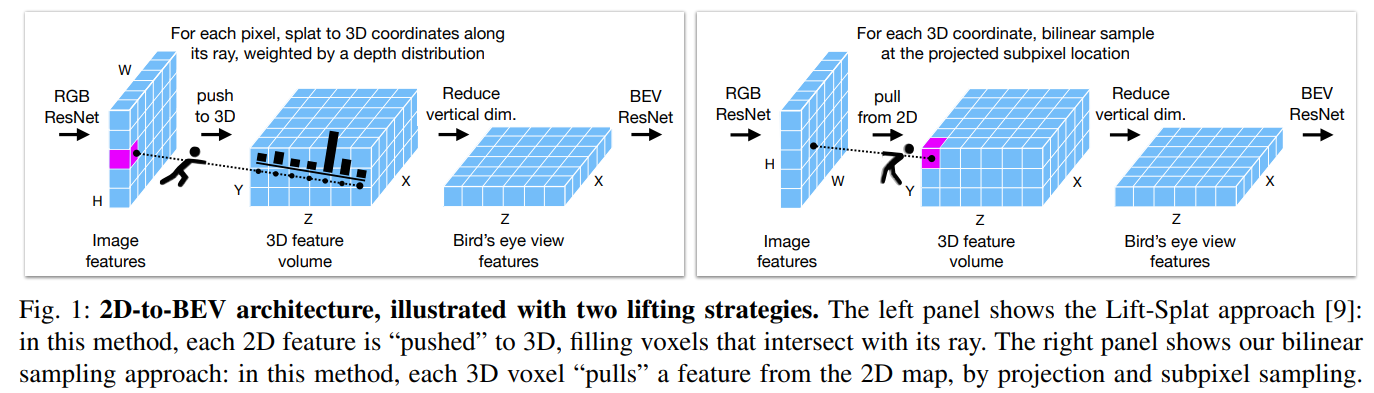
- Add more information

Results
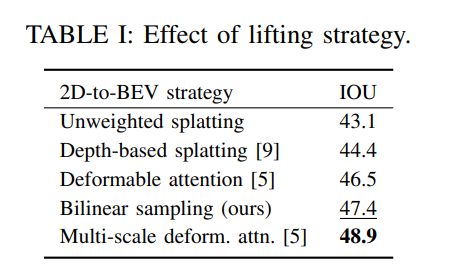
- Lifting strategy
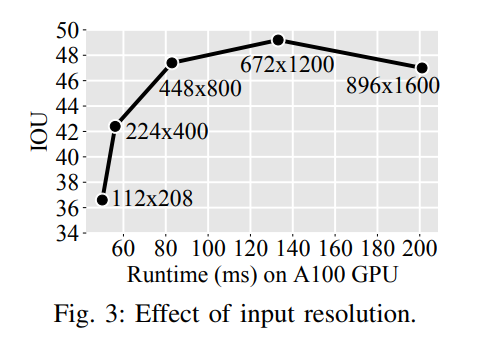
- Input resolution
- Fusion
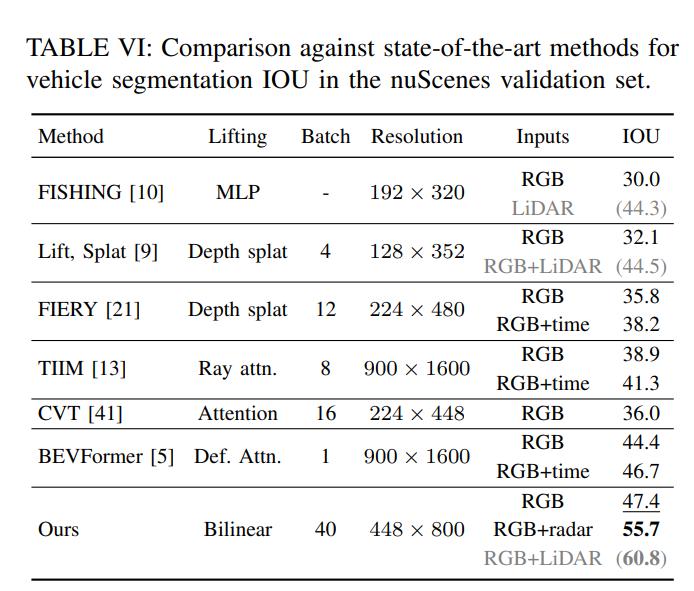
Conclusion
- Slow
- Public code
Orthographic Feature Transform for Monocular 3D Object Detection
[BMVC 2019]
Motivation
Given the high cost of existing LiDAR units, the sparsity of LiDAR point clouds at long ranges, and the need for sensor redundancy, accurate 3D object detection from monocular images remains an important research objective.
How orthographic birds-eye-vew representation could be constructed from a monocular image alone.
Contribution
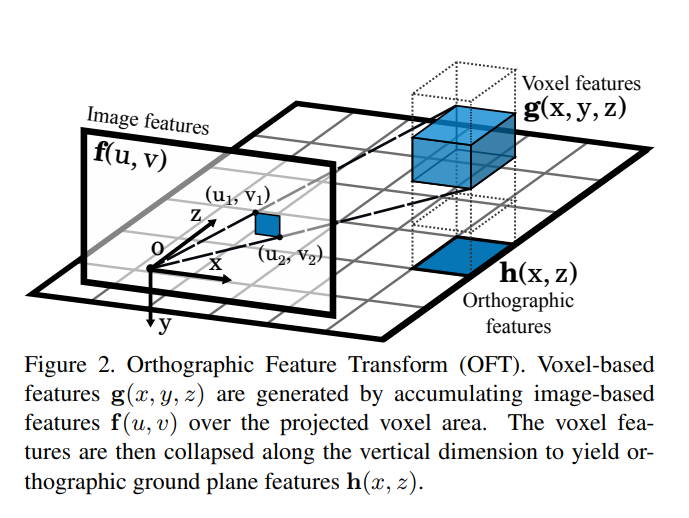
Introduce the orthographic feature transform (OFT) which maps perspective image-based features into an orthographic birds-eye-view, implemented efficiently using integral images for fast average pooling.
Describe a deep learning architecture for predicting 3D bounding boxes from monocular RGB images.
Highlight the importance of reasoning in 3D for the object detection task.
Method
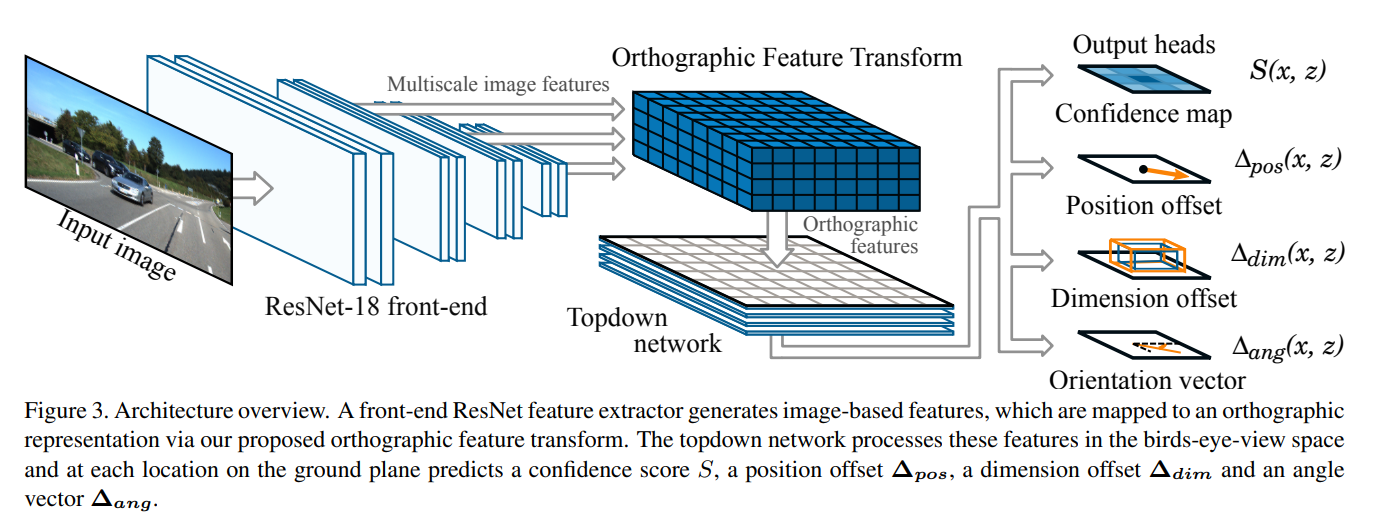
A front-end ResNet feature extractor which extracts multi-scale feature maps from the input image.
A orthographic feature transform which transforms the image-based feature maps at each scale into an orthographic birds-eye-view representation.
A topdown network, consisting of a series of ResNet residual units, which processes the birds-eye-view feature maps in a manner which is invariant to the perspective effects observed in the image.
A set of output heads which generate, for each object class and each location on the ground plane, a confidence score, position offset, dimension offset and a orientation vector.
A non-maximum suppression and decoding stage, which identifies peaks in the confidence maps and generates discrete bounding box predictions.
Results

Conclusions
- No depth => low accuracy
- No information about FPS
Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks
[CVPR 2020]
Motivation
Focus on the particularly chanllenging scenario of BEV map estimation from monocular images alone.
Create Grid map
Contribution
Propose a novel dense transformer layer which maps image-based feature maps into the birds-eyeview space.
Design a deep convolutional neural network architecture, which includes a pyramid of transformers operating at multiple image scales, to predict accurate birds-eye-view maps from monocular images.
Processing 23.2 frames per second on a single GeForce RTX 2080 Ti graphics card.
Method

The pyramid occupancy network consists of four main stages. A backbone feature extractor generates multiscale semantic and geometric features from the image. This is then passed to an FPN -inspired feature pyramid which upsamples low-resolution feature-maps to provide context to features at higher resolutions. A stack of dense transformer layers together map the image-based features into the birdseye view, which are processed by the topdown network to predict the final semantic occupancy grid probabilities.

Results
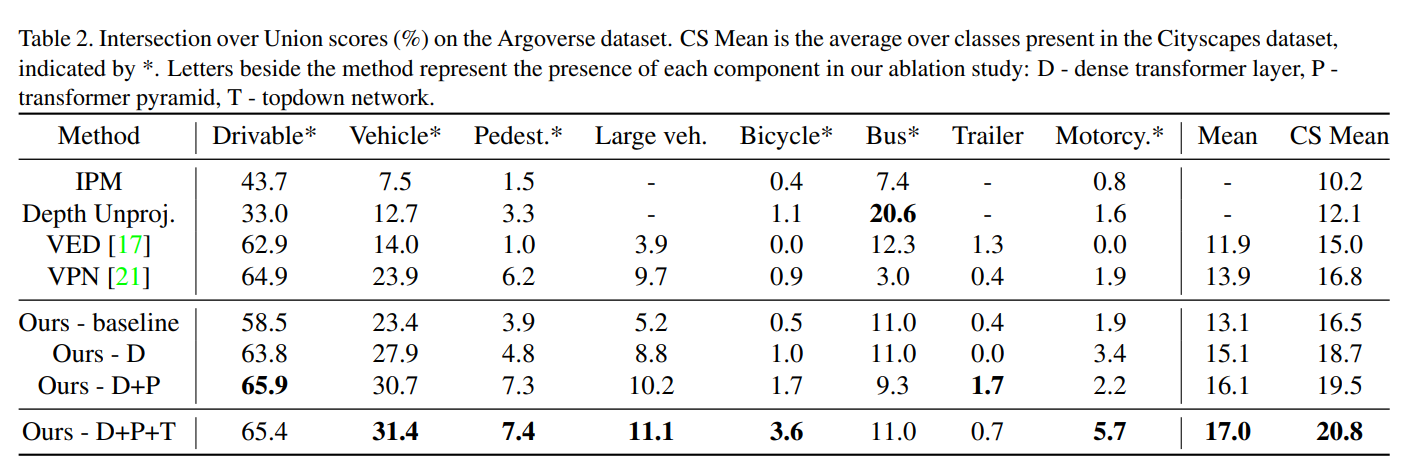

Conclusions
- Fast
- Don’t have detection head (focus on conduct the grid map)
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
[ECCV 2020]
Motivation
Preserves the 3 downside of multi-view setting in perception for autonomous.
Advantage of multiview:
Translation equivariance – If pixel coordinates within an image are all shifted, the output will shift by the same amount. Fully convolutional singleimage object detectors roughly have this property and the multi-view extension inherits this property from them [11] [6].
Permutation invariance the final output does not depend on a specific ordering of the n cameras.
Ego-frame isometry equivariance the same objects will be detected in a given image no matter where the camera that captured the image was located relative to the ego car. An equivalent way to state this property is that the definition of the ego-frame can be rotated/translated and the output will rotate/translate with it.
- The downside of the simple approach above is that using post-processed detections from the single-image detector prevents one from differentiating from predictions made in the ego frame all the way back to the sensor inputs. As a result, the model cannot learn in a data-driven way what the best way is to fuse information across cameras. It also means backpropagation cannot be used to automatically improve the perception system using feedback from the downstream planner.
=> remove the downside of multi-view setting in perception for autonomous.
Contributions
Propose a model named “Lift-Splat” that preserves the 3 symmetries identified above by design while also being end-to-end differentiable
Explain how our model “lifts” images into 3D by generating a frustum-shaped point cloud of contextual features, “splats” all frustums onto a reference plane as is convenient for the downstream task of motion planning.
Propose a method for “shooting” proposal trajectories into this reference plane for interpretable end-to-end motion planning.
Method
- Lift: Latent Depth Distribution
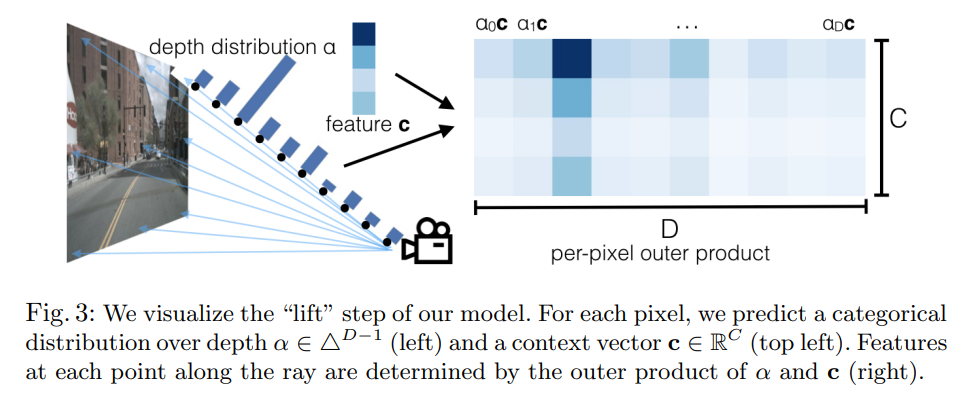
The first stage of our model operates on each image in the camera rig in isolation. The purpose of this stage is to “lift” each image from a local 2-dimensional coordinate system to a 3-dimensional frame that is shared across all cameras.
The challenge of monocular sensor fusion is that we require depth to transform into reference frame coordinates but the “depth” associated to each pixel is inherently ambiguous. Our proposed solution is to generate representations at all possible depths for each pixel.
- Splat: Pillar Pooling
We follow the pointpillars architecture to convert the large point cloud output by the “lift” step. “Pillars” are voxels with infinite height. We asign every point to its nearest pillar and perform sum pooling to create a C × H ×W tensor that can be processed by a standard CNN for bird’s-eye-view inference.
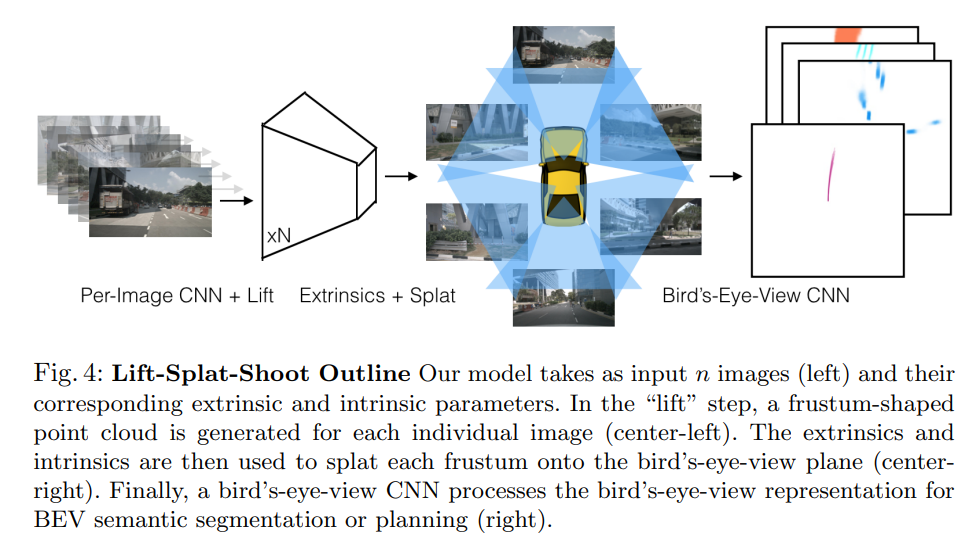
- Shoot: Motion Planning
Key aspect of our Lift-Splat model is that it enables end-to-end cost map learning for motion planning from camera-only input. At test time, planning using the inferred cost map can be achieved by “shooting” different trajectories, scoring their cost, then acting according to lowest cost trajectory.

In practice, we determine the set of template trajectories by running K-Means on a large number of expert trajectories.
Results

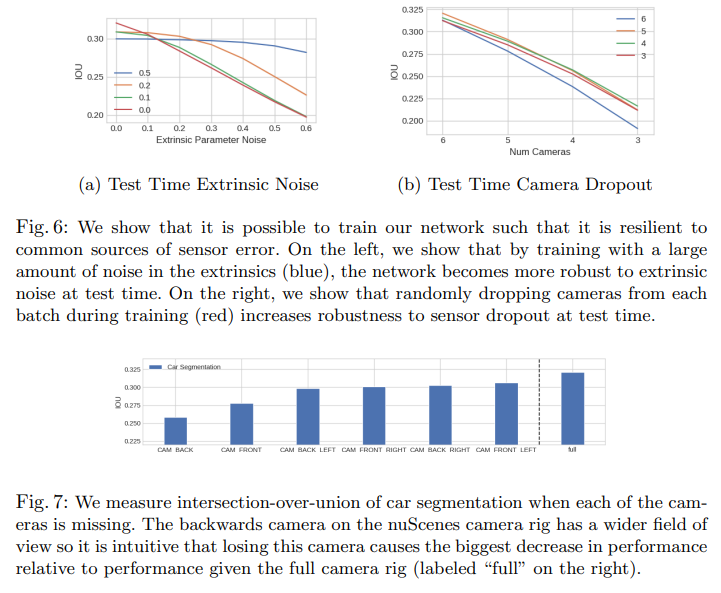
Conclusion
- Improve from OFT
- Fast? (35Hz in Titan V)
MonoLayout: Amodal scene layout from a single image
[WACV 2020]
Motivation
The novel and highly challenging task of estimating scene layout in bird’s eye view, given only a single color image.
Humans have a remarkable cognitive capability of perceiving amodal attributes of objects in an image. For example, upon looking at an image of a vehicle, humans can nominally infer the occluded parts, and also the potential geometry of the surroundings of the vehicle.
Contribution
Propose MonoLayout, a practically motivated deep architecture to estimate the amodal scene layout from just a single image.
Demonstrate that adversarial learning can be used to further enhance the quality of the estimated layouts, specifically when hallucinating large missing chunks of a scene.
Evaluate against several state-of-the-art approaches, and outperform all of them by a significant margin on a number of established benchmarks.
Show that MonoLayout can also be efficiently trained on datasets that do not contain lidar scans by leveraging recent successes in monocular depth estimation.
Method
In this paper, we address the problem of amodal scene layout estimation from a single color image. Formally, given a color image I captured from an autonomous driving platform, we aim to predict a bird’s eye view layout of the static and dynamic elements of the scene. Concretely, we wish to estimate the following three quantities. 1
The set of all static scene points S (typically the road and the sidewalk) on the ground plane (within a rectangular range of length L and width W, in front of the camera), regardless of whether or not they are imaged by the camera.
The set of all dynamic scene points D on the ground plane (within the same rectangular range as above) occupied by vehicles, regardless of whether or not they are imaged by the camera.
For each point discerned in the above step as being occupied by a vehicle, an instance-specific labeling of which vehicle the point belongs to.

Results
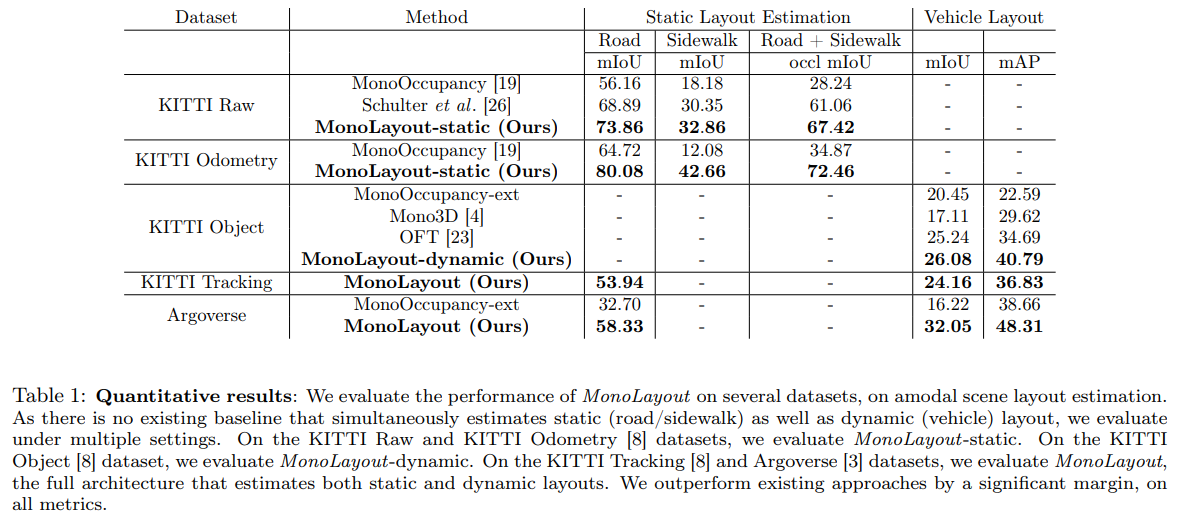

Conclusion
- First paper for layout creation
- Fast? (32 FPS in 1080Ti)
- No detection head
HFT: Lifting Perspective Representations via Hybrid Feature Transformation
[ICRA 2023]
Motivations
- To capture accurate BEV semantic maps, popular methods in industry community rely on expensive sensors such as LiDAR and radar. These methods require time-consuming computation to process cloud point data. Given the limited resolution and lack of sufficient semantic information of sensors, we focus on performing the BEV semantic segmentation by a single monocular RGB image.
Contributions
Empirically discuss the vital differences between Camera model-Based Feature Transformation (CBFT) and Camera model-Free Feature Transformation (CFFT). To the best of our knowledge, we are the first to point out that both the geometric priors in CBFT and the global spatial correlation in CFFT are important for BEV semantic segmentation.
Propose a novel end-to-end learning framework, named HFT, to reap the benefits and avoid the drawbacks of CBFT and CFFT to construct an accurate BEV semantic map using only a monocular FV image.
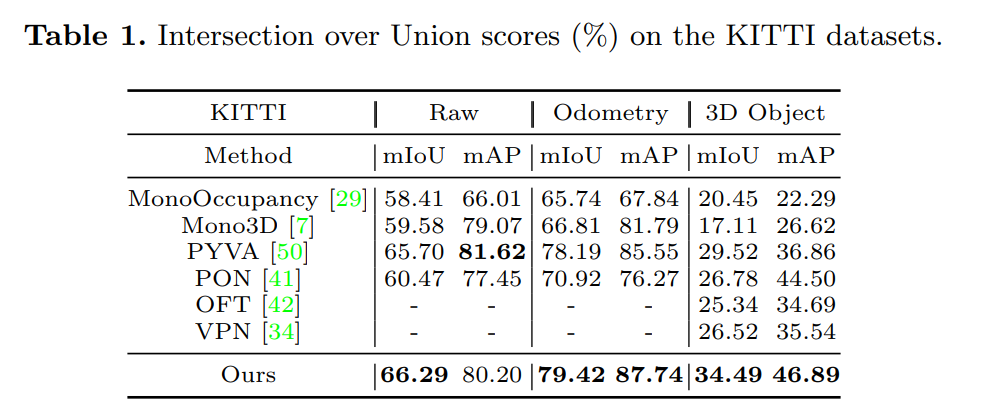
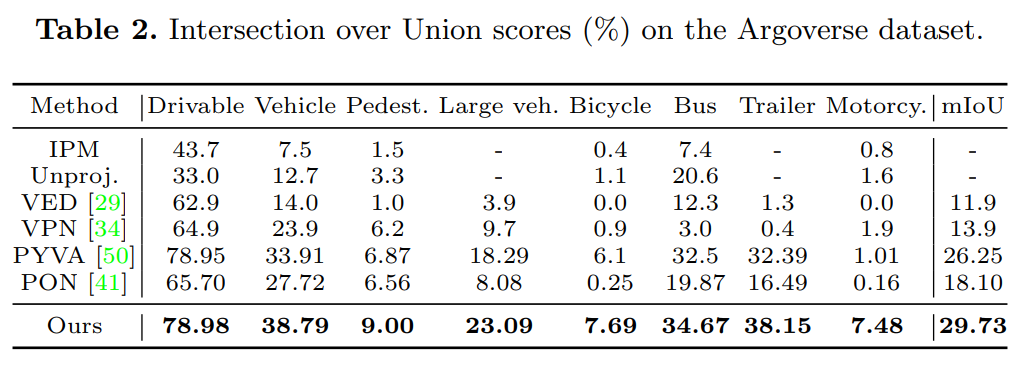
HFT is evaluated on public benchmarks and achieves state-of-the-art performance with negligible computing budget, i.e., at least relative 13.3% and 16.8% improvement than previous methods on the Argoverse and KITTI 3D Object datasets respectively.
Method
- CBFT vs CFFT
The differences between CBFT and CFFT are summarized as follows. CBFT exploits the geometric priors explicitly by incorporating the camera intrinsics into the view transformer module. Such approaches follow the IPM to project image features from FV to BEV. Reasonable semantic segmentation results from the camera coordinate system to the pixel coordinate system can be obtained on the premise that the optical axis of the camera is parallel to the ground. However, as for objects lying above the ground plane, CBFT is prone to result in inappropriate semantic maps. In other words, the flat-world assumption in IPM hinders segmentation performance in areas lying above the ground.
The main component of CFFT is MLP or attention mechanism, which works well in capturing global correlation in a pixel-wise manner. Thus, CFFT benefits from global spatial correlation. However, CFFT fails to yield BEV semantic maps with clear shapes or edges. The mIoU curve demonstrates that CFFT converges slower than CBFT. The key factor gives raise to the performance gap between CBFT and CFFT is whether the feature transformation employs the geometric priors. The visualization result of CFFT reveals that lacking geometric priors leads to imprecisely estimating the layout geometry.
- HFT
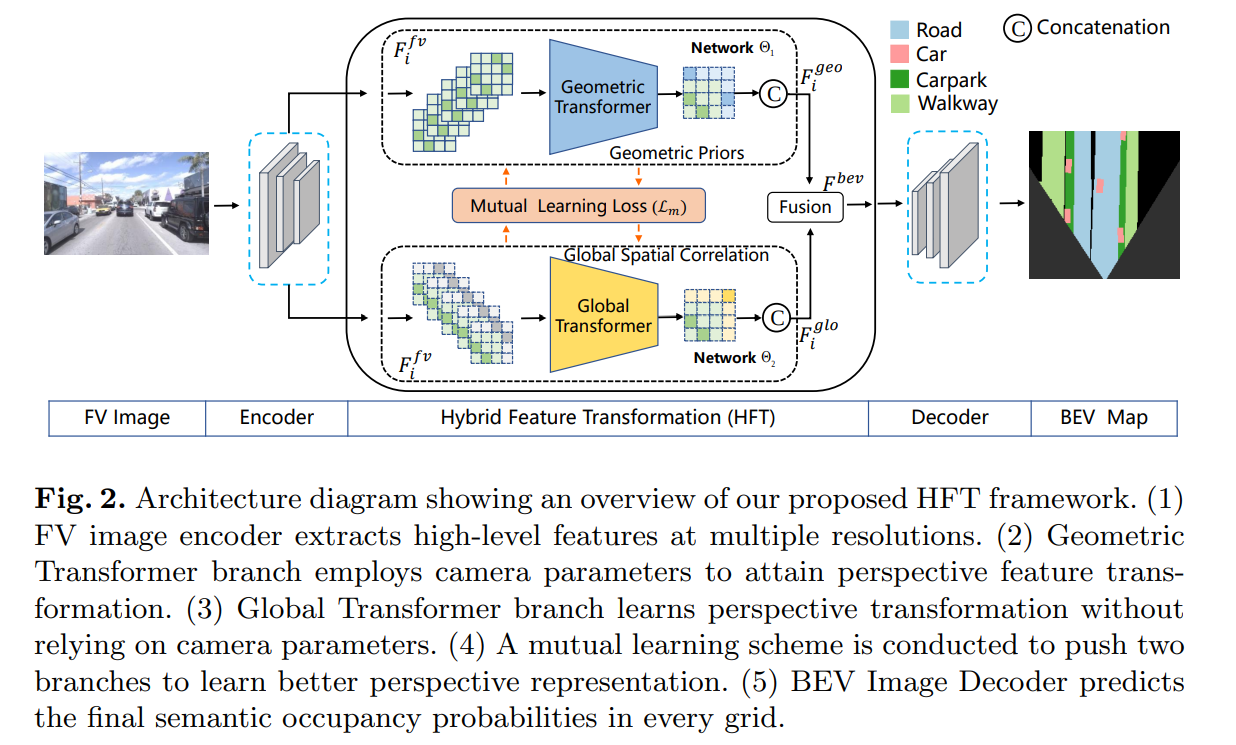
We follow the principle of reaping the benefits of both CBFT and CFFT while avoiding their drawbacks. In proposed HFT network, three kinds of modules are conducted in succession: a shared image-view encoder, HFT module and a semantic decode head. The shared image-view encoder adopts a shared backbone to extract FPN-style features with multiple scales. HFT module takes the high-level FV features as input and independently conducts two feature transformation. Furthermore, HFT employs a mutual learning strategy to pushing both CBFT branch (Geometric Transformer) and CFFT branch (Global Transformer) to learn more appropriate representations from each other. Thereafter, the semantic decode head deals with the semantic segmentation task for both dynamic and static elements in BEV.
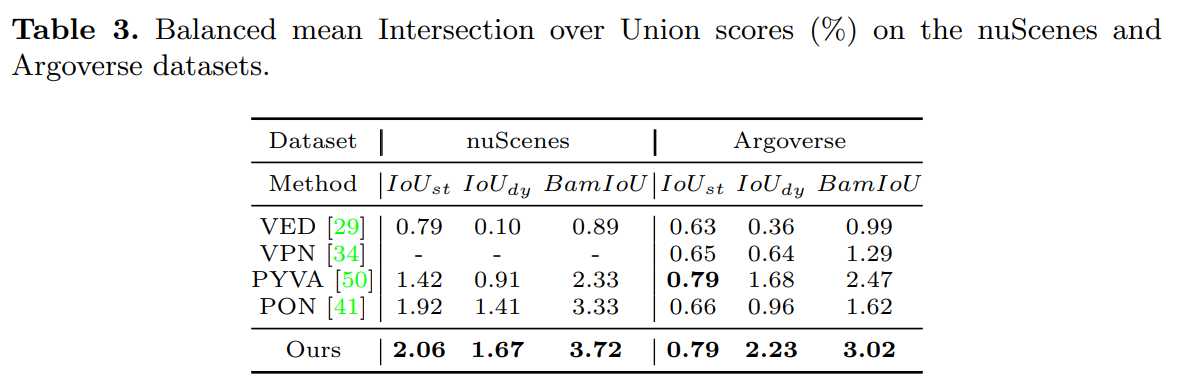
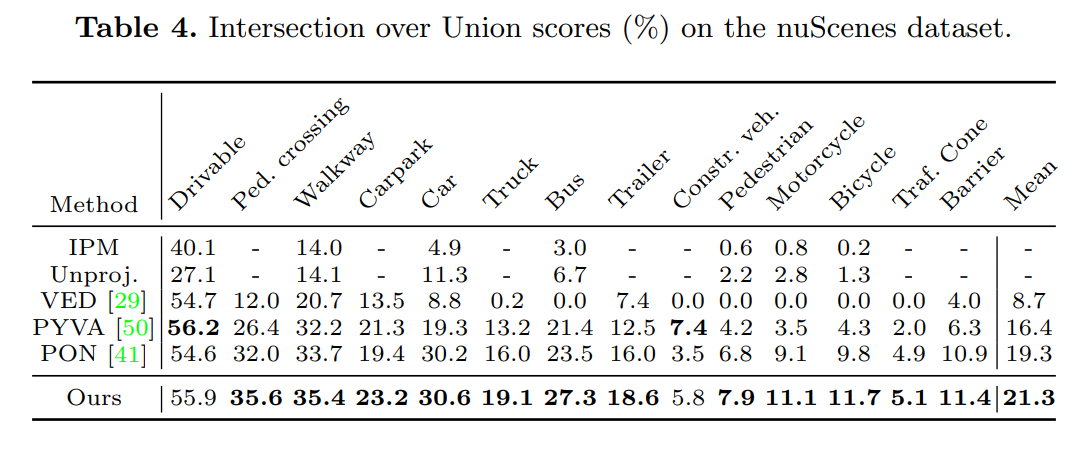
Results
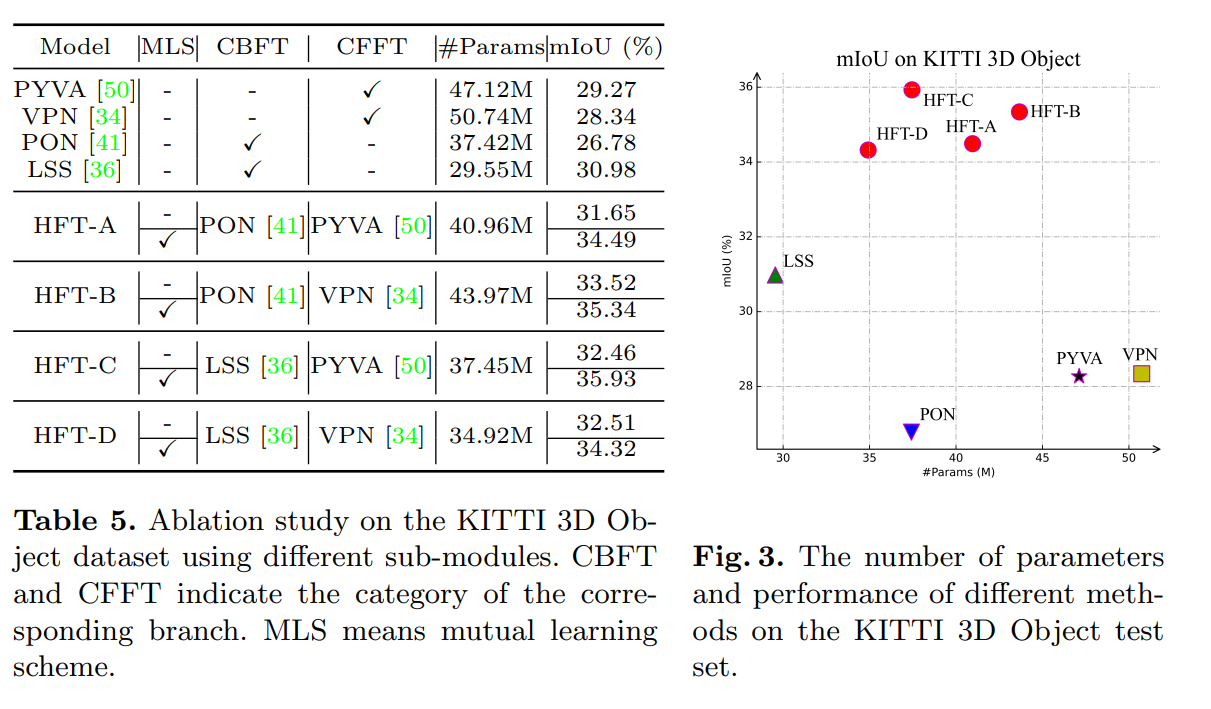
Conclusion
- Speed?