
Vision Transformers (ViT) in Image Recognition
While convolutional neural networks (CNNs) have been utilized in computer vision since the 1980s, AlexNet was the first to beat the performance of current state-of-the-art image recognition systems by a wide margin in 2012. This breakthrough was made possible by two factors: (i) the availability of training sets such as ImageNet, and (ii) the usage of commoditized GPU hardware, which allowed for substantially more training compute. As a result, CNNs have become the go-to model for vision tasks since 2012.
The advantage of utilizing CNNs was that they did away with the necessity for hand-drawn visual features, instead learning to complete jobs “end to end” from data. While CNNs do not need hand-crafted feature extraction, the architecture is built expressly for images and can be computationally intensive. Looking ahead to the next generation of scalable vision models, one can wonder if domain-specific design is still necessary, or if more domain-agnostic and computationally efficient architectures could be used to attain state-of-the-art outcomes.
The Vision Transformer (ViT) first appeared as a competitive alternative to CNN. In terms of computing efficiency and accuracy, ViT models exceed the present state-of-the-art (CNN) by almost a factor of four.
Transformer models have become the de-facto status quo in natural language processing (NLP). In computer vision research, there has recently been a rise in interest in Vision Transformers (ViTs) and Multilayer perceptrons (MLPs).
This article will cover the following topics:
- What is a Vision Transformer (ViT)?
- Using ViT models in Image Recognition
- How do Vision Transformers work?
- Use Cases and applications of Vision Transformers
Vision Transformer (ViT) in Image Recognition
While the Transformer architecture has become the highest standard for tasks involving natural language processing (NLP), its use cases relating to computer vision (CV) remain only a few. In computer vision, attention is either used in conjunction with convolutional networks (CNN) or used to substitute certain aspects of convolutional networks while keeping their entire composition intact. However, this dependency on CNN is not mandatory, and a pure transformer applied directly to sequences of image patches can work exceptionally well on image classification tasks.
Recently, Vision Transformers (ViT) have achieved highly competitive performance in benchmarks for several computer vision applications, such as image classification, object detection, and semantic image segmentation.
What is a Vision Transformer (ViT)?
The Vision Transformer (ViT) model was introduced in a research paper published as a conference paper at ICLR 2021 titled “An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale”. It was developed and published by Neil Houlsby, Alexey Dosovitskiy, and 10 more authors of the Google Research Brain Team.
The fine-tuning code and pre-trained ViT models are available at the GitHub of Google Research. You find them here. The ViT models were pre-trained on the ImageNet and ImageNet-21k datasets.
Are Transformers a Deep Learning method?
A transformer in machine learning is a deep learning model that uses the mechanisms of attention, differentially weighing the significance of each part of the input data. Transformers in machine learning are composed of multiple self-attention layers. They are primarily used in the AI subfields of natural language processing (NLP) and computer vision (CV).
Transformers in machine learning hold strong promises toward a generic learning method that can be applied to various data modalities, including the recent breakthroughs in computer vision achieving state-of-the-art standard accuracy with better parameter efficiency.
Difference between CNN and ViT (ViT vs. CNN)
Vision Transformer (ViT) achieves remarkable results compared to convolutional neural networks (CNN) while obtaining fewer computational resources for pre-training. In comparison to convolutional neural networks (CNN), Vision Transformer (ViT) show a generally weaker inductive bias resulting in increased reliance on model regularization or data augmentation (AugReg) when training on smaller datasets.
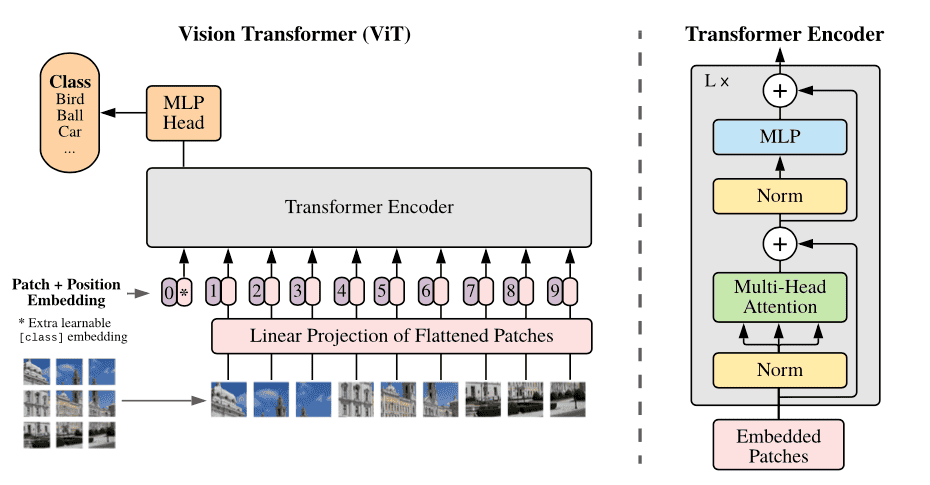
The ViT is a visual model based on the architecture of a transformer originally designed for text-based tasks. The ViT model represents an input image as a series of image patches, like the series of word embeddings used when using transformers to text, and directly predicts class labels for the image. ViT exhibits an extraordinary performance when trained on enough data, breaking the performance of a similar state-of-art CNN with 4x fewer computational resources.
These transformers have high success rates when it comes to NLP models and are now also applied to images for image recognition tasks. CNN uses pixel arrays, whereas ViT splits the images into visual tokens. The visual transformer divides an image into fixed-size patches, correctly embeds each of them, and includes positional embedding as an input to the transformer encoder. Moreover, ViT models outperform CNNs by almost four times when it comes to computational efficiency and accuracy.
The self-attention layer in ViT makes it possible to embed information globally across the overall image. The model also learns on training data to encode the relative location of the image patches to reconstruct the structure of the image.
The transformer encoder includes:
Multi-Head Self Attention Layer (MSP) : This layer concatenates all the attention outputs linearly to the right dimensions. The many attention heads help train local and global dependencies in an image.
Multi-Layer Perceptrons (MLP) Layer : This layer contains a two-layer with Gaussian Error Linear Unit (GELU).
Layer Norm (LN) : This is added prior to each block as it does not include any new dependencies between the training images. This thereby helps improve the training time and overall performance.
Moreover, residual connections are included after each block as they allow the components to flow through the network directly without passing through non-linear activations.
In the case of image classification, the MLP layer implements the classification head. It does it with one hidden layer at pre-training time and a single linear layer for fine-tuning.
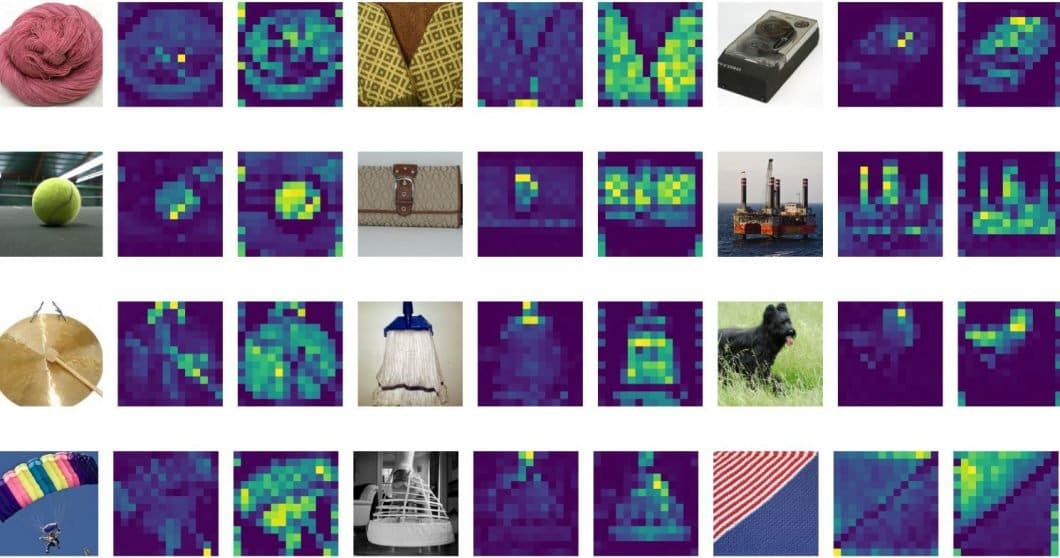
What are attention maps of ViT?
Attention, more specifically, self-attention is one of the essential blocks of machine learning transformers. It is a computational primitive used to quantify pairwise entity interactions that help a network to learn the hierarchies and alignments present inside input data. Attention has proven to be a key element for vision networks to achieve higher robustness.

Vision Transformer ViT Architecture
The overall architecture of the vision transformer model is given as follows in a step-by-step manner:
- Split an image into patches (fixed sizes)
- Flatten the image patches
- Create lower-dimensional linear embeddings from these flattened image patches
- Include positional embeddings
- Feed the sequence as an input to a state-of-the-art transformer encoder
- Pre-train the ViT model with image labels, which is then fully supervised on a big dataset
- Fine-tune on the downstream dataset for image classification
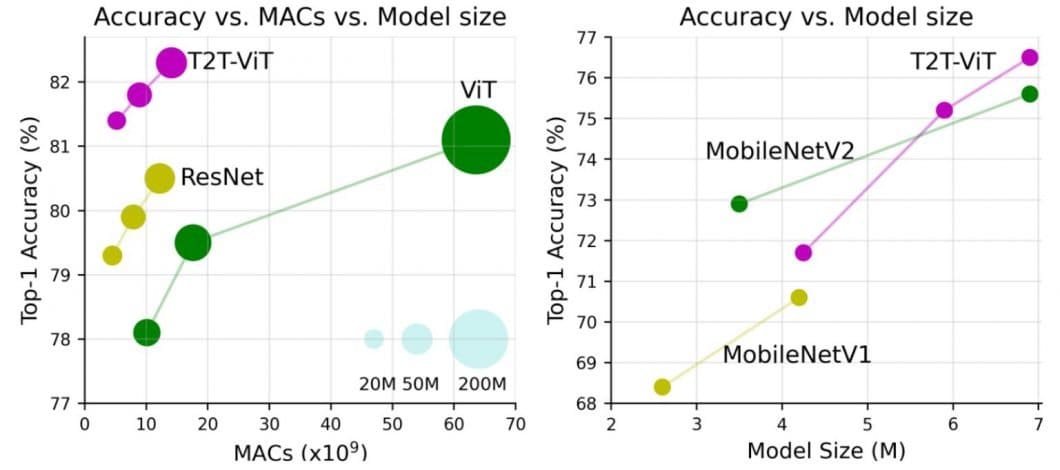
While the ViT full-transformer architecture is a promising option for vision processing tasks, the performance of ViTs is still inferior to that of similar-sized CNN alternatives (such as ResNet) when trained from scratch on a mid-sized dataset such as ImageNet.
How does a Vision Transformer (ViT) work?
The performance of a vision transformer model depends on decisions such as that of the optimizer, network depth, and dataset-specific hyperparameters. Compared to ViT, CNNs are easier to optimize.
The disparity on a pure transformer is to marry a transformer to a CNN front end. The usual ViT stem leverages a 16*16 convolution with a 16 stride. In comparison, a 3*3 convolution with stride 2 increases the stability and elevates precision.
CNN turns basic pixels into a feature map. Later, the feature map is translated by a tokenizer into a sequence of tokens that are then inputted into the transformer. The transformer then applies the attention technique to create a sequence of output tokens. Eventually, a projector reconnects the output tokens to the feature map. The latter allows the examination to navigate potentially crucial pixel-level details. This thereby lowers the number of tokens that need to be studied, lowering costs significantly.
Particularly, if the ViT model is trained on huge datasets that are over 14M images, it can outperform the CNNs. If not, the best option is to stick to ResNet or EfficientNet. The vision transformer model is trained on a huge dataset even before the process of fine-tuning. The only change is to disregard the MLP layer and add a new D times KD*K layer, where K is the number of classes of the small dataset.
To fine-tune in better resolutions, the 2D representation of the pre-trained position embeddings is done. This is because the trainable liner layers model the positional embeddings.
Real-World Vision Transformer (ViT) Use Cases and Applications
Vision transformers have extensive applications in popular image recognition tasks such as object detection, segmentation, image classification, and action recognition. Moreover, ViTs are applied in generative modeling and multi-model tasks, including visual grounding, visual-question answering, and visual reasoning.
Video forecasting and activity recognition are all parts of video processing that require ViT. Moreover, image enhancement, colorization, and image super-resolution also use ViT models. Last but not least, ViTs has numerous applications in 3D analysis, such as segmentation and point cloud classification.
Conclusion
The vision transformer model uses multi-head self-attention in Computer Vision without requiring the image-specific biases. The model splits the images into a series of positional embedding patches, which are processed by the transformer encoder. It does so to understand the local and global features that the image possesses. Last but not least, the ViT has a higher precision rate on a large dataset with reduced training time.